Investigating Chicago Crimes
OVERVIEW
For a weekend project, I decided to play around with some of Chicago’s publicly available crime data. The data spans 2001 to 2014 and is broken out by type of crime, description, location, etc. I used R and RMarkdown to generate this document, and I thought I’d upload the code that generates the tables, plots, etc. in case any of you out there are interested in that sort of thing. Enjoy!
p.s. Sorry for the miserable formatting of all text output from R…Squarespace is absolutely dreadful when it comes to handling text and code…
Loading packages.
Reading in data set (~1.2GB) and taking a quick look at the variables.
setwd("C:/Users/kwurt/Documents/R/Chicago Crimes") ptm = proc.time() df = read.csv("ChicagoCrimes01toPres.csv") proc.time() - ptm # save as RDS for backup saveRDS(df, "ChicagoCrimes01toPres.rds") # set up percentage formatting as_percent <- function(x, digits = 2, format = "f", ...) { paste0(formatC(100 * x, format = format, digits = digits, ...), "%") } glimpse(df)
## Variables: ## $ ID (int) 9803951, 9805538, 9803958, 9804026, 98039... ## $ Case.Number(fctr) HX453015, HX454384, HX453010, HX453033, ... ## $ Date (fctr) 10/02/2014 11:59:00 PM, 10/02/2014 11:59... ## $ Block(fctr) 073XX S MAY ST, 019XX W MONTEREY AVE, 01... ## $ IUCR (fctr) 1822, 4510, 0486, 0820, 0486, 0320, 0810... ## $ Primary.Type (fctr) NARCOTICS, OTHER OFFENSE, BATTERY, THEFT... ## $ Description(fctr) MANU/DEL:CANNABIS OVER 10 GMS, PROBATION... ## $ Location.Description (fctr) SIDEWALK, GOVERNMENT BUILDING/PROPERTY, ... ## $ Arrest (fctr) true, true, true, true, false, false, fa... ## $ Domestic (fctr) false, false, true, false, true, false, ... ## $ Beat (int) 733, 2212, 1021, 726, 215, 835, 1131, 182... ## $ District (int) 7, 22, 10, 7, 2, 8, 11, 18, 11, 8, 17, 10... ## $ Ward (int) 17, 19, 24, 15, 3, 18, 24, 42, 24, 23, 39... ## $ Community.Area (int) 68, 75, 29, 67, 38, 66, 25, 8, 26, 57, 16... ## $ FBI.Code (fctr) 18, 26, 08B, 06, 08B, 03, 06, 06, 18, 08... ## $ X.Coordinate (int) 1169969, 1165808, 1153332, 1165304, 11779... ## $ Y.Coordinate (int) 1855924, 1830858, 1892054, 1859629, 18741... ## $ Year (int) 2014, 2014, 2014, 2014, 2014, 2014, 2014,... ## $ Updated.On (fctr) 10/09/2014 12:39:21 PM, 10/09/2014 12:39... ## $ Latitude (dbl) 41.76, 41.69, 41.86, 41.77, 41.81, 41.76,... ## $ Longitude(dbl) -87.65, -87.67, -87.71, -87.67, -87.62, -... ## $ Location (fctr) (41.760149079, -87.652624608), (41.69145...
Doing some data manipulation to get dates in the right format and merge on names of community areas.
df$Date = as.Date(df$Date, format="%m/%d/%Y") df$Month = format(df$Date, format="%m") df$Day = format(df$Date, format="%d") df$Updated.On = as.Date(df$Updated.On, format="%m/%d/%Y") CAMapping = read.csv("CommunityAreaMapping.csv") # using base R for merge since `dplyr` doesn't have outer joins implemented yet df = merge(df, CAMapping, by.x="Community.Area", by.y="Code", all.x=TRUE)
PRELIMINARY INVESTIAGATION
Now that we have the data read in and in a format we’d like, let’s start off by visualizing the change in crimes over each year. Note that 2014 is a partial year.
source('theme_fivethirtyeight.R') crimesByYearAndMonth = df %>% group_by(Year, Month) %>% summarize(Crimes=n()) %>% mutate(FreqWithinYear=as_percent(Crimes/sum(Crimes)), Date=paste(Month,Year,sep="/")) ggplot(data=(crimesByYearAndMonth %>% group_by(Year) %>% summarize(Crimes=sum(Crimes))), aes(x=as.character(Year), y=Crimes)) + geom_bar(stat="identity", fill="#6C1B1B") + scale_y_continuous(labels = comma) + xlab("Year") + ggtitle("Number of Crimes Reported in Chicago by Year") + theme_fivethirtyeight()
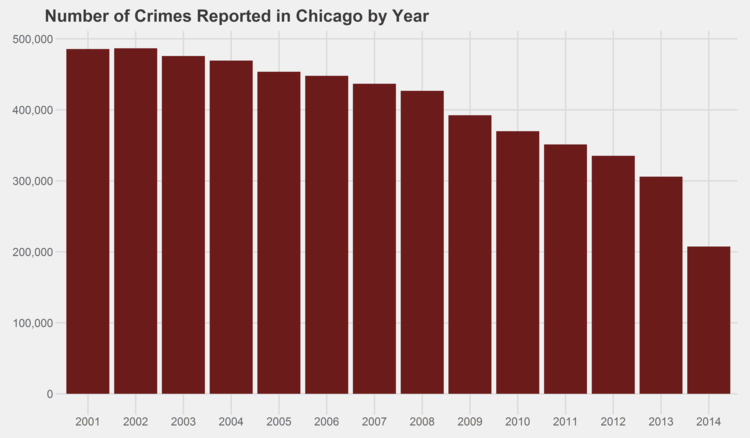
That’s a pretty encouraging sight! The number of crimes reported has dropped a whopping -37% from 2001 to 2013!
Next, let’s take a look at crimes by month. 2014 data was removed to prevent biasing October, November, and December crime counts. Crime appears to be lower in Winter months. The low February value is likely due in part to the shorter month.
ggplot(data=(crimesByYearAndMonth %>% filter(Year<2014) %>% group_by(Month) %>% summarize(Crimes=sum(Crimes))), aes(x=as.character(Month), y=Crimes)) + geom_bar(stat="identity", fill="#6C1B1B") + scale_y_continuous(labels = comma) + xlab("Month") + ggtitle("Number of Crimes Reported in Chicago by Month") + theme_fivethirtyeight()

INVESTIGATING CRIME TYPES
Let’s dig into the details a little more and cut the data by crime type. We’ll start off by taking a peak at the type of crimes at our disposal and investigating their distributions.
df %>% group_by(Primary.Type) %>% summarize(Crimes=n()) %>% mutate(Freq=as_percent(Crimes/sum(Crimes))) %>% arrange(desc(Crimes))
## Source: local data frame [36 x 3] ## ## Primary.Type Crimes Freq ## 1 THEFT 1159912 20.55% ## 2 BATTERY 1032638 18.30% ## 3 CRIMINAL DAMAGE 652219 11.56% ## 4 NARCOTICS 644456 11.42% ## 5 OTHER OFFENSE 347812 6.16% ## 6 ASSAULT 340481 6.03% ## 7 BURGLARY 333490 5.91% ## 8 MOTOR VEHICLE THEFT 270101 4.79% ## 9 ROBBERY 211067 3.74% ## 10 DECEPTIVE PRACTICE 185524 3.29% ## 11 CRIMINAL TRESPASS 166165 2.94% ## 12 PROSTITUTION 64438 1.14% ## 13 WEAPONS VIOLATION 53697 0.95% ## 14 PUBLIC PEACE VIOLATION 40465 0.72% ## 15 OFFENSE INVOLVING CHILDREN 34820 0.62% ## 16 SEX OFFENSE 20620 0.37% ## 17 CRIM SEXUAL ASSAULT 20283 0.36% ## 18 GAMBLING 13473 0.24% ## 19 LIQUOR LAW VIOLATION 13019 0.23% ## 20 ARSON 9323 0.17% ## 21 HOMICIDE 6830 0.12% ## 22 INTERFERENCE WITH PUBLIC OFFICER 6644 0.12% ## 23 KIDNAPPING 5926 0.10% ## 24 INTERFERE WITH PUBLIC OFFICER 3760 0.07% ## 25 INTIMIDATION 3381 0.06% ## 26 STALKING 2645 0.05% ## 27 OFFENSES INVOLVING CHILDREN 382 0.01% ## 28 OBSCENITY 291 0.01% ## 29 PUBLIC INDECENCY 115 0.00% ## 30 OTHER NARCOTIC VIOLATION 101 0.00% ## 31 RITUALISM 23 0.00% ## 32 NON-CRIMINAL 21 0.00% ## 33 NON - CRIMINAL 13 0.00% ## 34 CONCEALED CARRY LICENSE VIOLATION 11 0.00% ## 35 NON-CRIMINAL (SUBJECT SPECIFIED) 3 0.00% ## 36 DOMESTIC VIOLENCE 1 0.00%
Unsurprisingly, theft makes up the largest category of crime. The combination of all types of theft (theft, burglary, motor vehicle theft, and robbery) makes up 35% of all crimes. I was somewhat surprised that narcotics (11%) didn’t make up a greater percentage of total crimes…it would be interesting to see how Chicago’s distribution of narcotics crimes compared to cities like New York and Los Angeles…but since I don’t have NY or LA data readily available, let’s move on!
INVESTIGATING CRIME TYPES BY MONTH
Earlier, we saw that crime appeared to be higher in Summer months than Winter months. This makes sense for crimes like theft (warmer weather means more people — especially tourists — on the streets, which in turn means more opportunities for theft to occur), but what about other types of crimes? Do they all follow this pattern?
As it turns out, it’s a mixed bag. Generally, most see a spike in the summer months, but there are several notable exceptions, including criminal trespassing, deceptive practices, kidnapping, motor vehicle theft, offenses involving children, and prostitution.
I was particularly intrigued by the pattern of prostitution, which drops severely in December and then reaches its highest point in January. That pattern makes sense from a behavioral and economic perspective (less demand around the holidays), but I wasn’t necessarily expecting that prior to looking at the data. It would be interesting to get some kind of data on the frequency of infidelity and compare that to the patterns in prostitution.
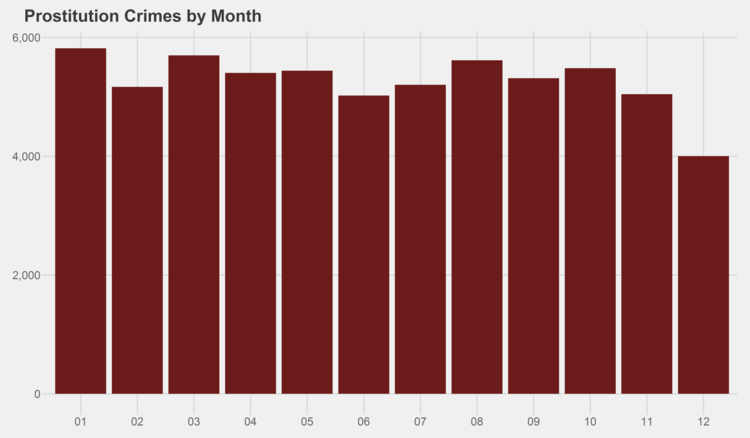
Similar graphs for each of the crime types can be found in the appendix at the bottom of this page. I especially recommend checking out the trends for gambling, both by month and by year…some curious patterns there.
INVESTIGATING PERCENT CHANGE BY CRIME TYPE
We saw that, overall, crime dropped -37% from 2001 to 2013. Naturally, I was curious to see which types of crimes were driving this drop. The percent changes by crime type can be found in the table below:
crimes_01 = df %>% filter(Year==2001) %>% group_by(Primary.Type) %>% summarize(Crimes01=n()) crimes_13 = df %>% filter(Year==2013) %>% group_by(Primary.Type) %>% summarize(Crimes13=n()) crimes_01to13 = merge(crimes_01,crimes_13,by.x="Primary.Type",by.y="Primary.Type",all.x=T,all.y=T) rm(crimes_01,crimes_13) crimes_01to13 = crimes_01to13 %>% filter(Crimes01 > 50, Crimes13 > 50) %>% mutate(PercentChange = as_percent(Crimes13/Crimes01-1,1)) %>% arrange(Crimes13/Crimes01) print(crimes_01to13)
## Primary.Type Crimes01 Crimes13 PercentChange ## 1 KIDNAPPING 935 243 -74.0% ## 2 PROSTITUTION 6026 1651 -72.6% ## 3 LIQUOR LAW VIOLATION 1637 464 -71.7% ## 4 ARSON 1012 364 -64.0% ## 5 SEX OFFENSE 2208 982 -55.5% ## 6 MOTOR VEHICLE THEFT 27504 12598 -54.2% ## 7 INTIMIDATION 280 133 -52.5% ## 8 CRIMINAL DAMAGE 55850 30855 -44.8% ## 9 ASSAULT 31377 17965 -42.7% ## 10 BATTERY 93439 53990 -42.2% ## 11 OTHER OFFENSE 29667 17954 -39.5% ## 12 CRIMINAL TRESPASS 13238 8135 -38.5% ## 13 HOMICIDE 667 417 -37.5% ## 14 GAMBLING 934 596 -36.2% ## 15 ROBBERY 18428 11825 -35.8% ## 16 CRIM SEXUAL ASSAULT 1787 1197 -33.0% ## 17 NARCOTICS 50576 34137 -32.5% ## 18 BURGLARY 26009 17889 -31.2% ## 19 THEFT 99259 71464 -28.0% ## 20 STALKING 204 150 -26.5% ## 21 WEAPONS VIOLATION 4278 3243 -24.2% ## 22 DECEPTIVE PRACTICE 14895 12812 -14.0% ## 23 OFFENSE INVOLVING CHILDREN 2228 2258 1.3% ## 24 PUBLIC PEACE VIOLATION 2751 3135 14.0%
It’s nice to see that crime has dropped pretty much across the board. It was also nice to see that some of the “scarier” crimes, such as assault/battery, kidnapping, sex offenses, and homicides have dropped even more than the overall average. I’m not saying theft and narcotics aren’t problems, but I’d certainly rather live in a city where those two are making up a higher percentage of total crimes relative to violent crimes like assault/battery and homicide. So it’s nice that we’re continuing to shift in that direction. That said, there’s still way too many violent crimes on this list for my liking…
INVESTIGATING CRIME BY NEIGHBORHOOD
The last thing I wanted to look into was how crimes varied by neighborhood. I got a little lazy with my code here (I always seem to fail at being able to create nice choropleths in R quickly…), so sorry that it’s sloppy. Just look at the pretty graphs instead.
# look at 2001-present
commAreas = readShapeSpatial("ChicagoCommunityAreas/CommAreas.shp")
trim <- function (x) gsub("^\\s+|\\s+$", "", x)
crimesByCA = df %>%
group_by(CommunityArea) %>%
summarize(crimes01to14 = n())
crimesByCA = crimesByCA %>%
filter(!is.na(CommunityArea)) %>%
mutate(COMMUNITY = toupper(trim(CommunityArea))) %>%
select(COMMUNITY, crimes01to14)
crimesByCA$COMMUNITY[crimesByCA$COMMUNITY=="LAKEVIEW"] = "LAKE VIEW"
crimesByCA$COMMUNITY[crimesByCA$COMMUNITY=="O'HARE"] = "OHARE"
commAreas@data = data.frame(commAreas@data, crimesByCA[match(commAreas@data$COMMUNITY, crimesByCA$COMMUNITY),])
spplot(commAreas, "crimes01to14", col.regions=brewer.pal(6, "Reds"),
main="Crimes by Chicago Neighborhood (01-14)",
at=c(0,25000,50000,100000,150000,250000,350000))

# look at 2014 only crimesByCA = df %>% filter(Year==2014) %>% group_by(CommunityArea) %>% summarize(crimes14 = n()) crimesByCA = crimesByCA %>% filter(!is.na(CommunityArea)) %>% mutate(COMMUNITY = toupper(trim(CommunityArea))) %>% select(COMMUNITY, crimes14) crimesByCA$COMMUNITY[crimesByCA$COMMUNITY=="LAKEVIEW"] = "LAKE VIEW" crimesByCA$COMMUNITY[crimesByCA$COMMUNITY=="O'HARE"] = "OHARE" commAreas = readShapeSpatial("ChicagoCommunityAreas/CommAreas.shp") commAreas@data = data.frame(commAreas@data, crimesByCA[match(commAreas@data$COMMUNITY, crimesByCA$COMMUNITY),]) spplot(commAreas, "crimes14", col.regions=brewer.pal(8, "Reds"), main="Crimes by Chicago Neighborhood (2014)", at=c(0,1000,2000,3000,4000,5000,7500,10000,15000))

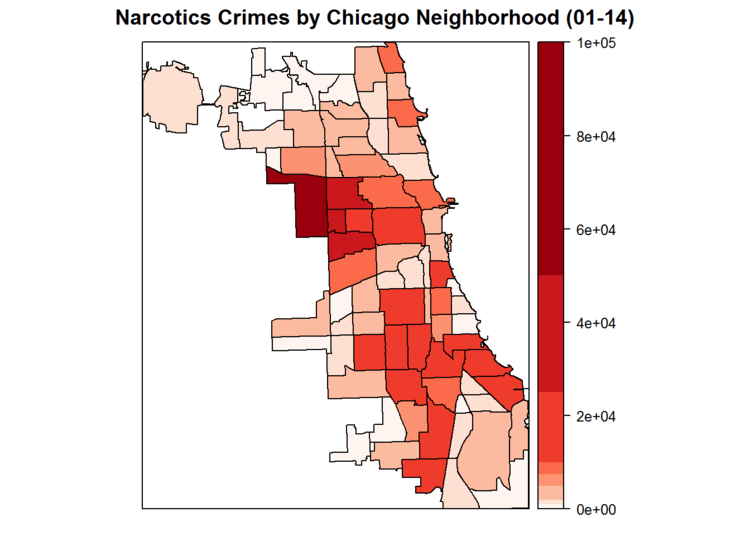
The first thing that jumped out to me was that Austin had such dreadfully high crime numbers. I didn’t think that Austin was really that bad, so I figured I’d delve into the data a bit to see if the distribution of crimes in Austin varied significantly from the distribution of crimes overall.
ChicagoDist = df %>% group_by(Primary.Type) %>% tally() %>% mutate(ChicagoDist=n/sum(n)) %>% select(Primary.Type, ChicagoDist) AustinCrimes = df %>% filter(CommunityArea=="Austin") %>% group_by(Primary.Type) %>% tally() %>% arrange(desc(n)) %>% mutate(AustinDist=n/sum(n)) %>% select(Primary.Type, AustinDist) AustinCrimes = merge(AustinCrimes, ChicagoDist, by.x="Primary.Type", by.y="Primary.Type", all.x=T, all.y=T) %>% arrange(desc(AustinDist)) %>% filter(AustinDist>.05 | ChicagoDist>.05) %>% mutate(Type=Primary.Type, Austin=as_percent(AustinDist,0), Chicago=as_percent(ChicagoDist,0)) %>% select(Type,Austin,Chicago) print(AustinCrimes)
## Type Austin Chicago ## 1 NARCOTICS 25% 11% ## 2 BATTERY 20% 18% ## 3 THEFT 13% 21% ## 4 CRIMINAL DAMAGE 9% 12% ## 5 OTHER OFFENSE 6% 6% ## 6 ASSAULT 6% 6% ## 7 BURGLARY 4% 6%
Without digging too deep into the data, it appears likely that the reason that Austin has such worse crime numbers relative to the rest of Chicago is tied to narcotics. I’d been toying around with plotting the narcotics by neighborhood already, and seeing this further convinced me. So here’s my last plot of the day:
crimesByCA = df %>% filter(Primary.Type=="NARCOTICS") %>% group_by(CommunityArea) %>% summarize(crimesNarc = n()) crimesByCA = crimesByCA %>% filter(!is.na(CommunityArea)) %>% mutate(COMMUNITY = toupper(trim(CommunityArea))) %>% select(COMMUNITY, crimesNarc) crimesByCA$COMMUNITY[crimesByCA$COMMUNITY=="LAKEVIEW"] = "LAKE VIEW" crimesByCA$COMMUNITY[crimesByCA$COMMUNITY=="O'HARE"] = "OHARE" commAreas = readShapeSpatial("ChicagoCommunityAreas/CommAreas.shp") commAreas@data = data.frame(commAreas@data, crimesByCA[match(commAreas@data$COMMUNITY, crimesByCA$COMMUNITY),]) spplot(commAreas, "crimesNarc", col.regions=brewer.pal(8, "Reds"), main="Narcotics Crimes by Chicago Neighborhood (01-14)", at=c(0,1000,2000,5000,7500,10000,25000,50000,100000))
Alright, that’s it for me. If you enjoyed this data/R excursion and want to see more like this in the future, let me know!
p.s. If you’re more of the pessimistic type, you might want to read this article about how the Chicago Policy might be covering up crime stats.
APPENDIX
# generate graphs for all crime types by month simpleCap <- function(x) { s <- strsplit(x, " ")[[1]] paste(toupper(substring(s, 1,1)), tolower(substring(s, 2)), sep="", collapse=" ") } for (type in levels(df$Primary.Type)) { if (nrow(df %>% filter(Year<2014, Primary.Type==type)) > 0) { ggplot(data=(df %>% filter(Year<2014, Primary.Type==type) %>% group_by(Month) %>% summarize(Crimes=n())), aes(x=as.character(Month), y=Crimes)) + geom_bar(stat="identity", fill="#6C1B1B") + scale_y_continuous(labels = comma) + xlab("Month") + ggtitle(paste(simpleCap(type), "Crimes by Month")) + theme_fivethirtyeight() ggsave(paste("Plots/Crimes Reported by Month/",type,".png",sep=""), dpi=600, width=12, height=7) } }
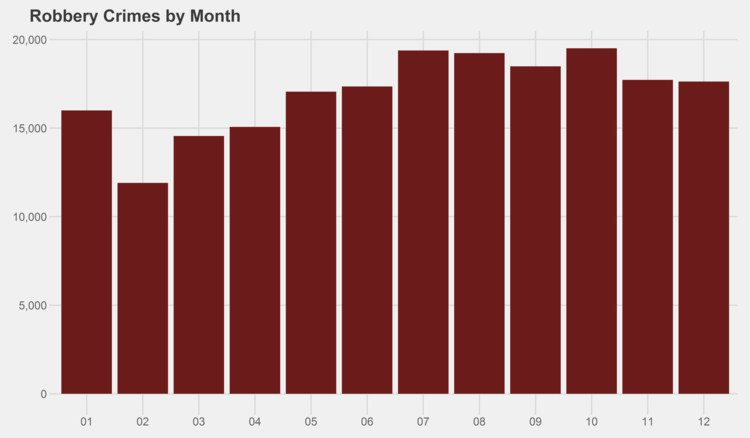
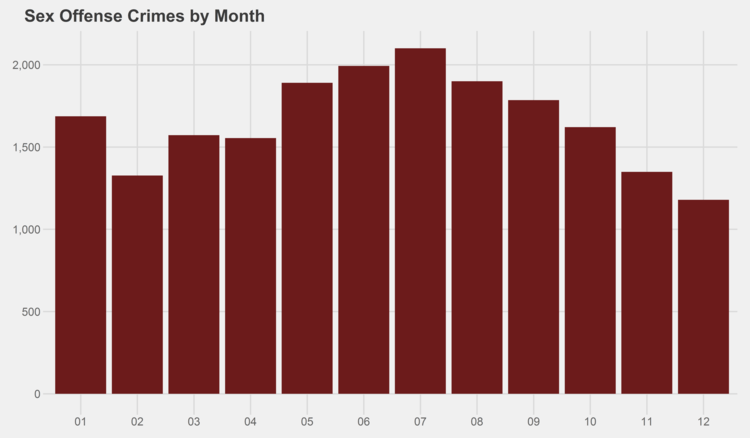
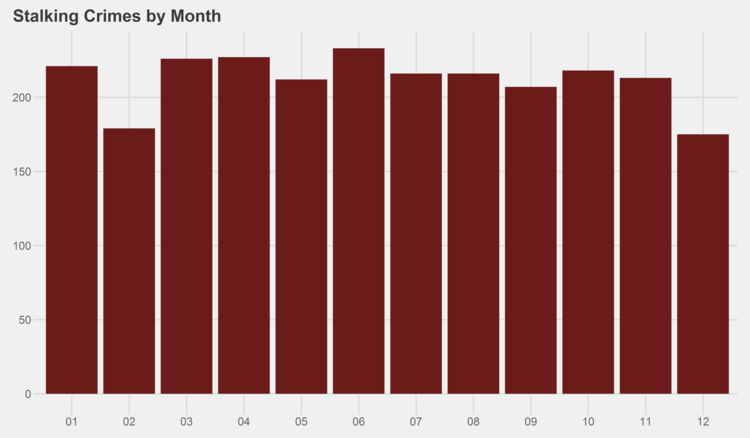
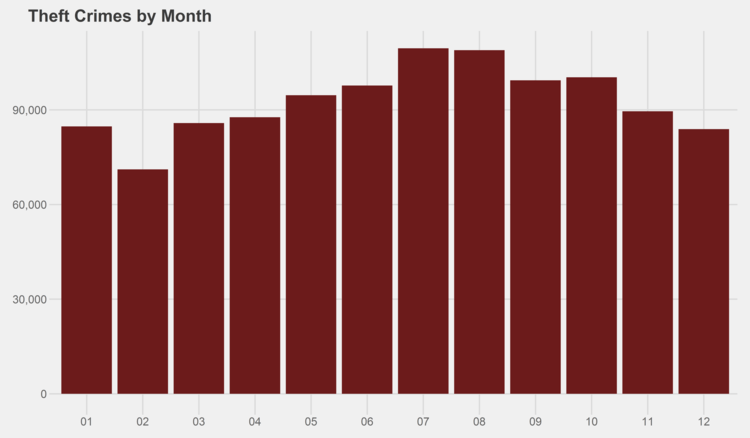


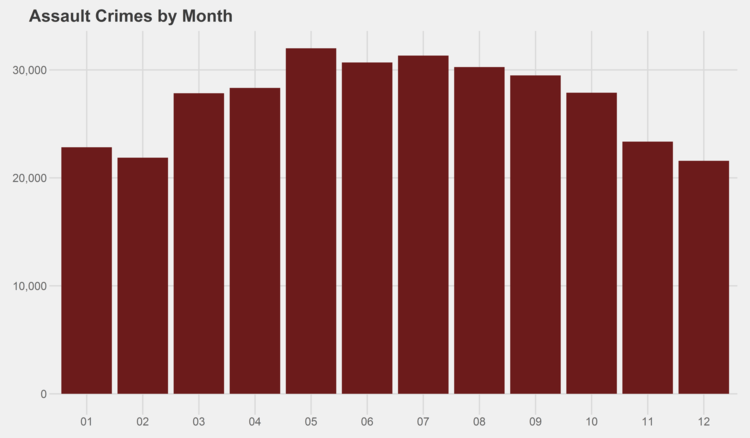


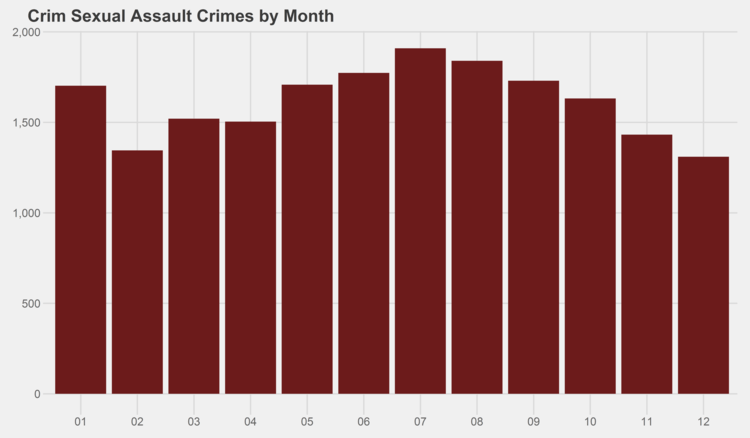
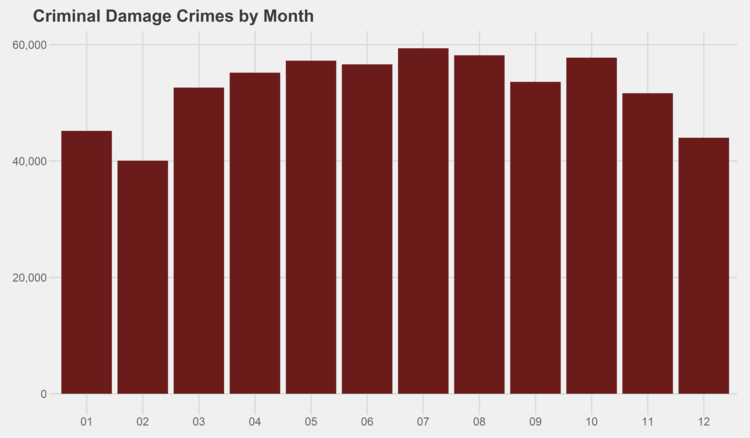

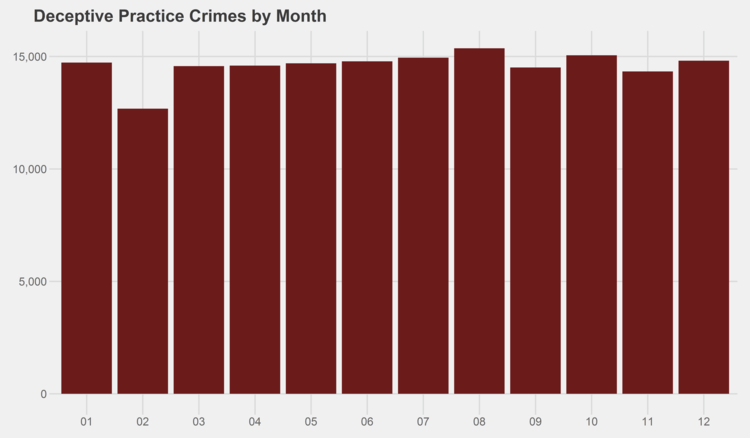





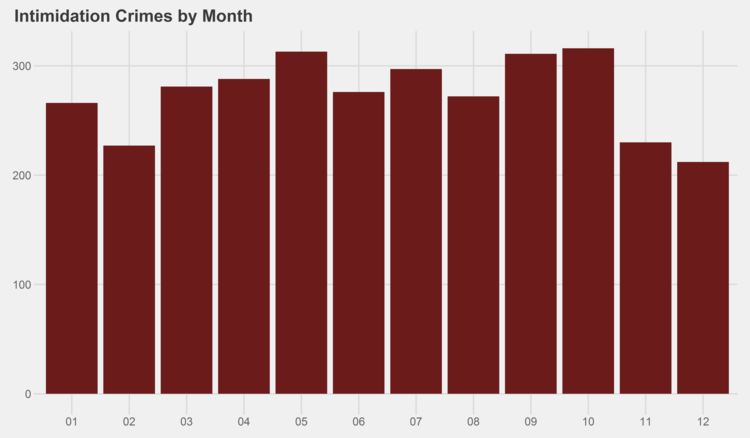
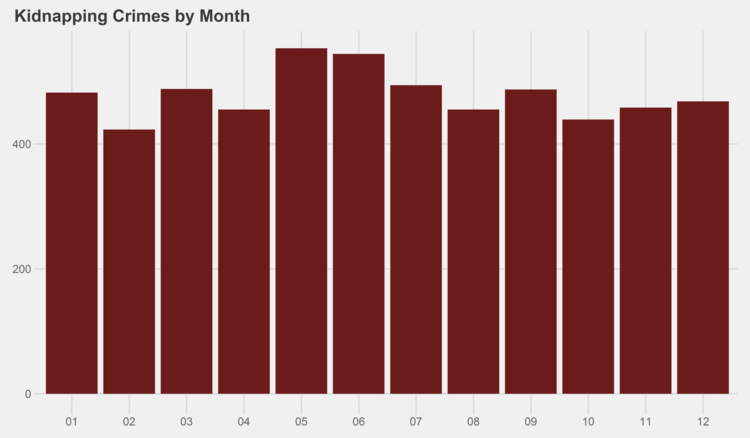


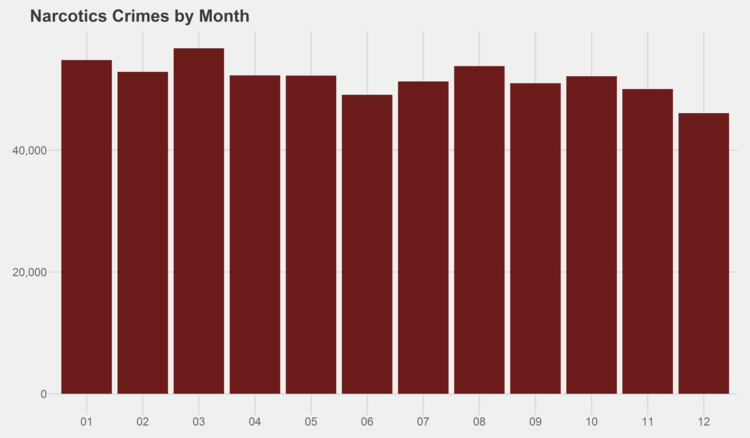



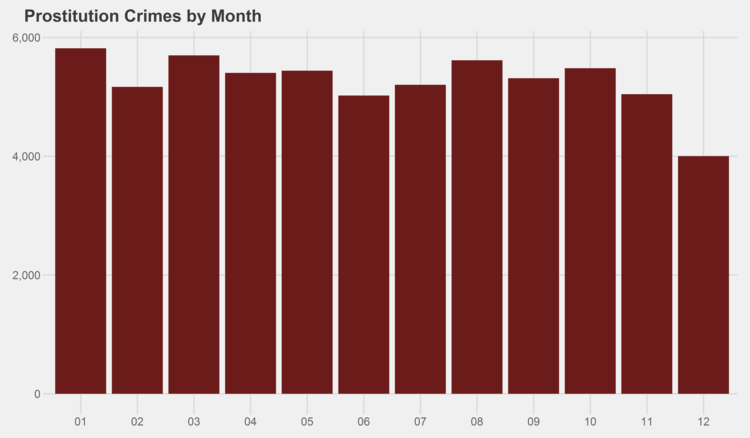

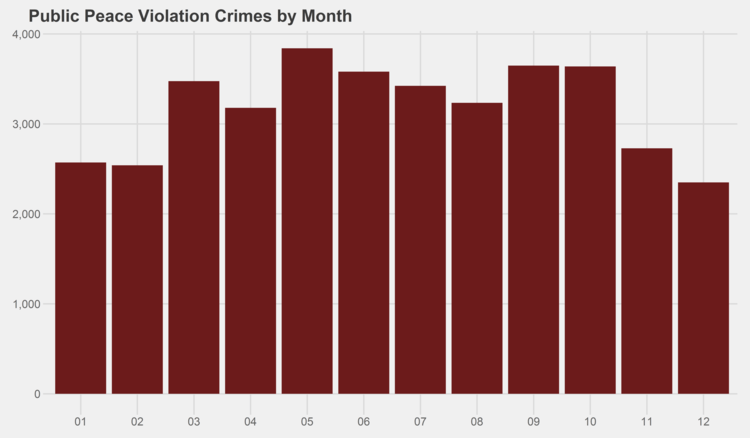

# generate graphs for all crime types by year for (type in levels(df$Primary.Type)) { if (nrow(df %>% filter(Primary.Type==type)) > 0) { ggplot(data=(df %>% filter(Primary.Type==type) %>% group_by(Year) %>% summarize(Crimes=n())), aes(x=as.character(Year), y=Crimes)) + geom_bar(stat="identity", fill="#6C1B1B") + scale_y_continuous(labels = comma) + xlab("Year") + ggtitle(paste(simpleCap(type), "Crimes by Year")) + theme_fivethirtyeight() ggsave(paste("Plots/Crimes Reported by Year/",type,".png",sep=""), dpi=600, width=12, height=7) } }