A Method for Predicting the Outcome of NBA Games
WHAT’S THIS POST ABOUT?
as is the case with any sports fan, i’m in love with the process of guessing which team will emerge victorious. and because i’m exceptionally nerdy, i love to use stats to develop rules for my guesses. over the years, as the sports worlds have gone deeper down the rabbit hole of advanced analytics, the stats at my disposal have become more advanced. simultaneously, my mathematical and statistical abilities have been improving dramatically, and i’m now at a point where i feel like my “guesses” are really more like reliable predictions.

over the past 6 months or so, i’ve been working on developing a method to predict the outcomes of NBA games. while the method is still very much a work in progress, it’s reached the point that it’s sufficiently flushed out for me to discuss. in part, i’m writing this to entertain you, dear reader, but i’m also writing this to document the status of my method at this point in time, as i fully anticipate it to evolve and improve over the coming months and i would like to be able to look back at this post at some point in the future and marvel at my naïveté…
LET’S MAKE A MODEL!
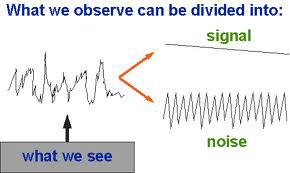
models, models, models. the analytical world is rapidly transitioning to these things, largely due to the fact that they are extremely adept at explaining fluctuations in data. and if you can explain the fluctuations, then they move from being random noise to being explainable signal. the better you are at identifying what’s the true signal in your data, the more you’re able to understand about the world you’re trying to predict. this is good.

i have a very humble modeling background, and i really had no idea what i was doing when i started working on building a model for NBA basketball games. i knew that my general goal was to come up with an equation that would help me understand why teams won or lost games, but that was it. i didn’t know what type of model i was going to use, what type of stats would be predictive, what software i should use to build the model (i ended up using Wizard, and i highly recommend it), etc.
one thing i did know was that i needed data. lots of data. and good data, at that. having spent the last year working in a department with pretty extreme data issues, i’m extremely sensitive to the garbage in, garbage out principle that demands credible, clean data as input in order for the output to be actionable intelligence. so, i wrote a program to extract the box score data from NBA.com for every single game from last year’s season. this gave me a hefty chunk of data to work with, although if i was being really thorough i probably should have used five or so years of data.
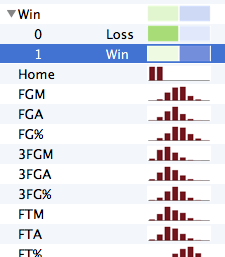
since the box score data is pretty bare-bones, i had to do quite a bit of calculations to get the advanced statistics that i knew would hold more predictive value. thankfully, there are quite a few resources online for advanced basketball statistics, and these formulas weren’t difficult to obtain. once i had as many potentially relevant statistics as i could think of, i threw all my data into Wizard and started playing around.
my general approach was to start with statistics/variables that were highly correlated with the “win” indicator, and then move on to the lesser correlated variables until it seemed like adding more variables wasn’t providing a significant amount of added predictability (mostly measured by loglikelihood and/or adjusted R^2). one of the great things about models is that they’re able to account for the correlation between variables, which meant that i didn’t have to worry about overreacting to a certain predictor (e.g., if FG% and 3pt.FG% are both highly predictive of a team winning, but they’re also highly correlated with each other, the model wouldn’t “double-count” the predictiveness of a team’s shooting proficiency). this was nice, because it made building the model somewhat idiot-proof.
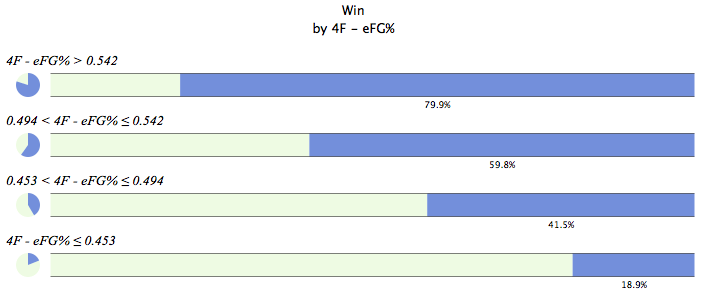
in the end, i decided to go with a rough Four Factor model. it wasn’t too surprising that i ended up here, since it’s been pretty well documented over the last few years that the stats that were most explanatory of whether a team wins were effective field goal percentage (eFG% — takes into account the fact that a 3pt. shot is worth 1.5x more than a 2pt. shot), turnover percentage (TO%), offensive rebounding percentage (OREB%), and free throw attempt rate (FTA% — percent of possessions that result in a team getting free throws). i didn’t really expect to find a new statistic that was more explanatory than these variables, but at least by running my model i was able to determine my own coefficients for these stats (the coefficients essentially provide weight to the importance of each stat).
MOVING FROM FITTING TO PREDICTING…
the model that i ended up with used the values for the four factors for both teams to suggest which team would would win the game. when comparing the model’s output to what actually happened (yay, backtesting!), the model performed extremely well (i.e., it was correct a very high percentage of the time). this was important because it meant that the things that i was using to explain the fluctuations in the data really were explaining most of the fluctuations. i was properly separating signal and noise. but that’s really only half the battle…
my model did a good job of explaining why a team wins a game, but that doesn’t help me predict what’s going to happen in the future. for example, i know that a team’s shooting proficiency is incredibly predictive, but i don’t know what a team’s eFG% in a game will be before the game starts. in other words, my model is useless without the inputs (own eFG%, opponent eFG%, own TO%, opponent TO%, etc.). we’re back to the garbage in, garbage out principle.
i need to turn my model into a predictive model, and the primary way that i do that is by tweaking the inputs. this is more or less the stage that i’m currently in (and will probably continue to be in for quite some time).
the obvious starting point is to use the team’s season values (e.g., if a team’s eFG% on the season is 50%, use this as the own eFG% input, and if the team’s opponent has an eFG% on the season of 51%, use that as the opponent eFG% input). this works alright (this method correctly predicts about 68% of games, according to my backtesting on the 227 games played thus far this year), but it breaks down frequently because it doesn’t take into consideration the team’s opponent. for example, if the Wizards are playing the Pacers, this approach suggests that the Pacers will emerge victorious, but it’ll be a pretty evenly matched game. this is largely due to the fact that the Wizards have a slightly better eFG% than the Pacers, and this is only just barely offset by the Pacers’ advantage in other factors. if you’ve been watching these teams play this year, you know that this outcome is pretty laughable — the Pacers are a much, much better team than the Wizards and the model’s output should be more confident in a Pacers victory.

the issue here is pretty obvious — the Pacers are an excellent defensive team, but their excellent defense isn’t accounted for with this approach. yes, the Wizards are effectively shooting 50% on the year, but Pacers hold opponents to an eFG% of 42%. is it likely that the Wizards will shoot 50% against the Pacers? no. it’s possible, but it’s not likely. thus, it doesn’t make sense to use 50% as the input to the model. this brings us to the first adjustment i’m currently making to make this a predictive model: i’m averaging the team’s season values with the opponent’s season values for their opponents. so, in this example, i’d use 46% (average of 50% and 42%) as the input for the Wizards eFG%. after making this adjustment, the model’s correct prediction percentage jumps from 68% to 75%.

the other adjustment that i’m currently making is taking into account whether the team is playing at home or on the road. i’m sure some of you were ready to cry out when i was discussing predictive variables and i didn’t mention home/away (the Nuggets were 38-3 at home last year — how could that NOT be included in the model??)…but the reason home/away wasn’t included is that it’s highly correlated with all of the team’s other stats. for example, the Nuggets effectively shot 52.6% at home last year and just 50.5% on the road last year. because the model accounts for correlation between variables, all of the home/away predictiveness was included in the values of the other stats, and thus adding home/away as a variable yielded virtually no added value. but that was just for determining a model to fit the data…we’re now in full-on predictive mode, and as such we need to account for things that we know about ahead of time that we can expect to affect our inputs.
for example, when we’re trying to predict what the Pacers will effectively shoot in their fictional road game against the Wizards, we can choose to use the team’s eFG% on road games as the input rather than their overall season eFG%. the assumption here is that the Pacers shoot differently on the road than at home, and that we can adjust their eFG% input into the model accordingly. adding this home/away adjustment adds another 3% of predictive power, bringing the model’s correct prediction percentage to 78%. not bad.

SO WHAT’S NEXT?
there are a ton of considerations that are floating around in my mind that i didn’t address in this post. for example, when making the opponent adjustment, why take a straight average? it’s likely that one team is better at controlling the game and their opponent’s performance than the other, so perhaps that average should be weighted more heavily based on the one team’s value than the other team’s. furthermore, i didn’t even address the credibility of the inputs (a team’s stats after 12 games are much less predictive than they are after 70 games) or the time that the model is run (what about an in-game model using the teams’ stats from that game, not their season averages? or perhaps a credibility-weighting of the two?).
because all of this data manipulation and backtesting takes a fair amount of time, and because this is just something i play with on holidays and weekends, i don’t have nearly enough time to incorporate all these things into the prediction methodology. i’ll continue making incremental improvements, and hopefully that correct prediction percentage will continue to creep upwards…
if you have any ideas or feedback on my method, please let me know via comment or email!
